Agents for discovery
I wanted to automate the discovery process for a new product. I had run this exact process at VTB on the B2B deposits case, together with consultants from McKinsey. Back then, going from interviews to a prioritized USM took the team about four months.
This time I wanted to check: can I get the same outcome with a pipeline of agents?
What I built
A set of agents and skills that walk through the full pipeline — from request to a finished Service Blueprint and User Story Map. The output is a structure you only need to decompose and put into the backlog for years ahead.

Folder of agents and skills — each one owns a single step of the pipeline
Then I ran it against the same dataset we had at VTB, but framed it as test data — so the model wouldn't be primed with the known answer.
The result surprised me
Clustering — almost 1:1 with what the team produced. One error: the agent inserted quote codes instead of the quotes themselves. I had to fix the skill so it pulls the full text.

Real clustering we built on the project
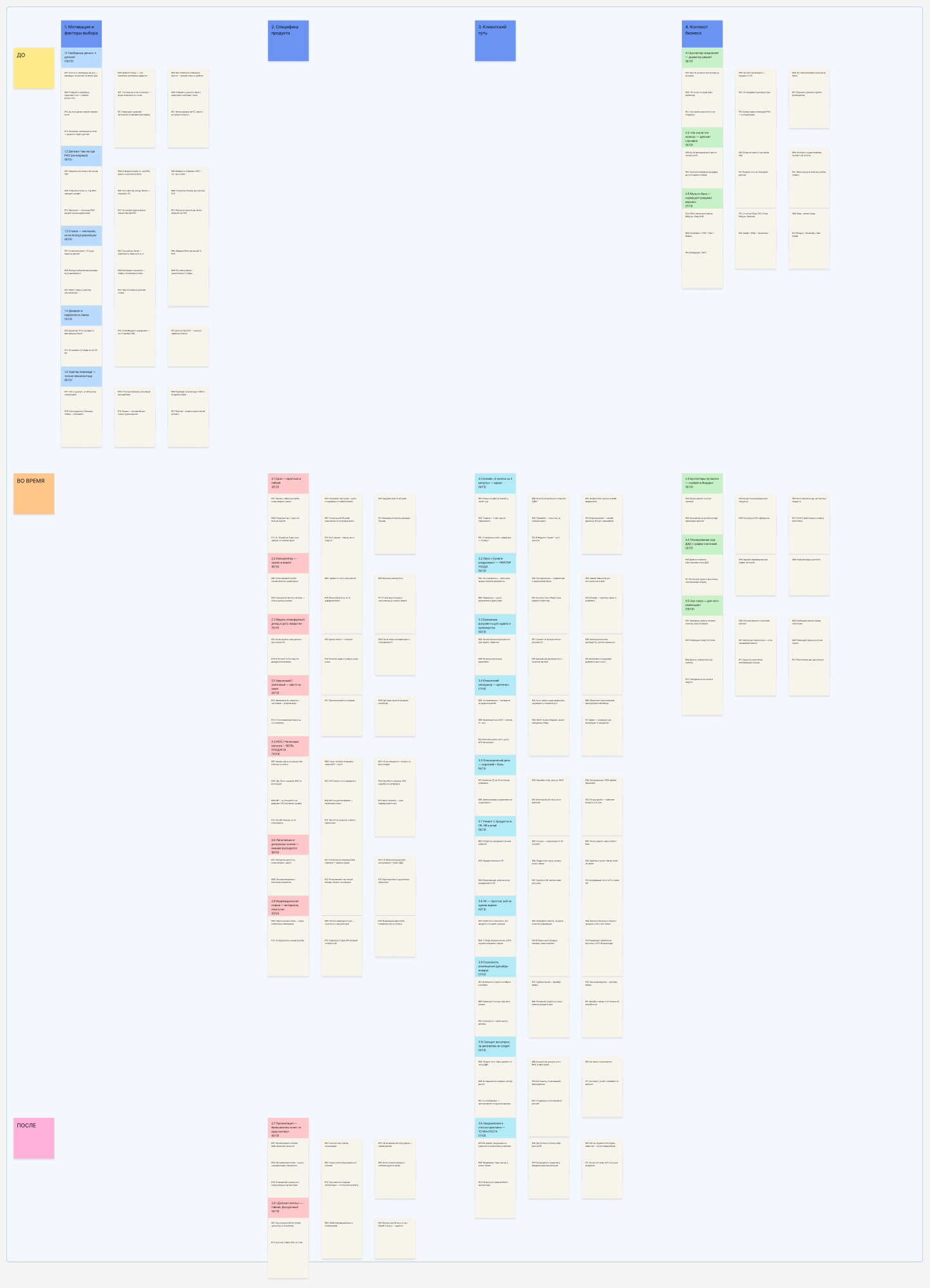
Agent version — structure is almost 1:1
Personas — the agent picked different axes and ended up with qualities that complement our personas. Not a copy — a different slice of the same sample. I like the result.
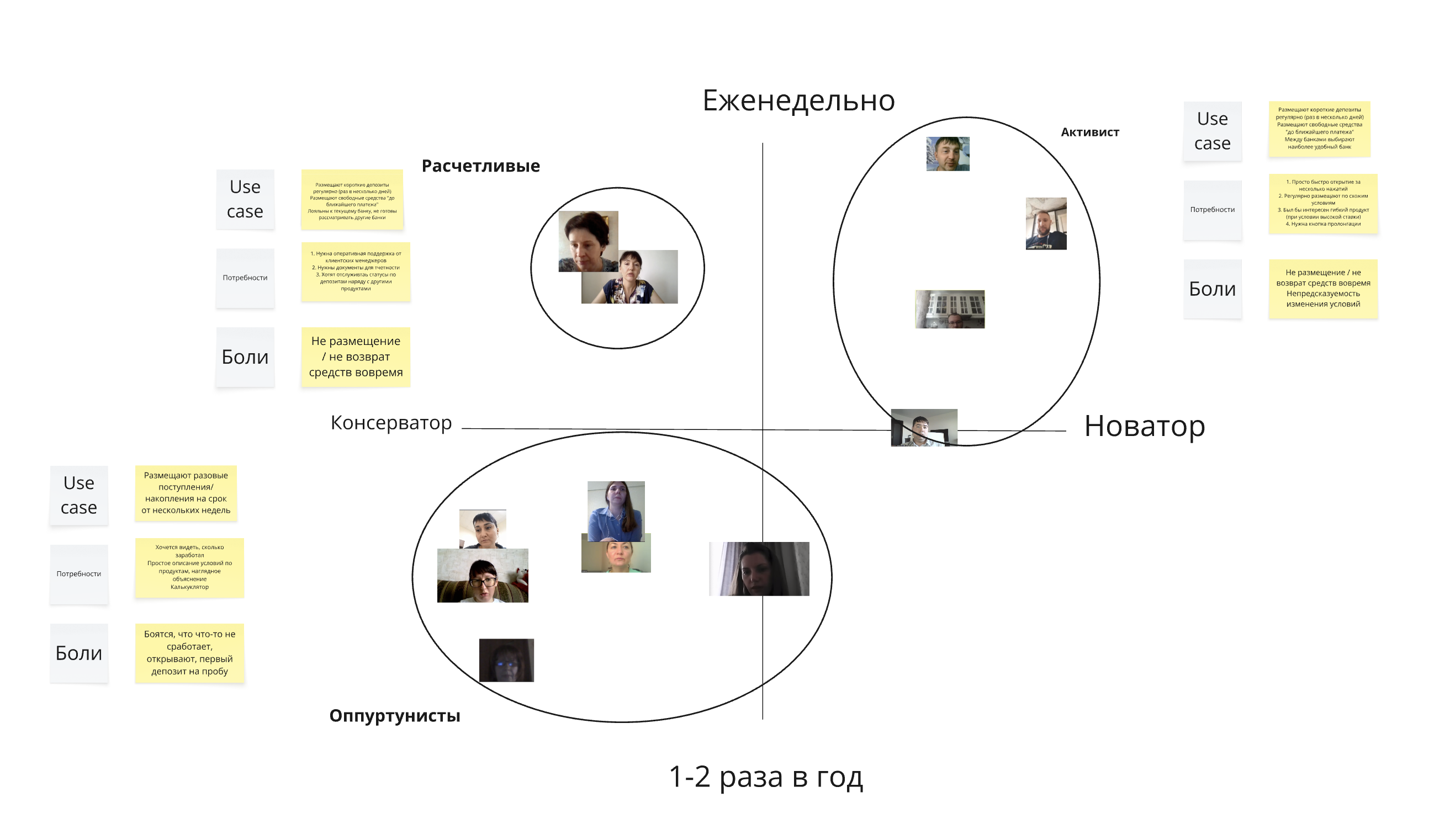
Personas the team built together
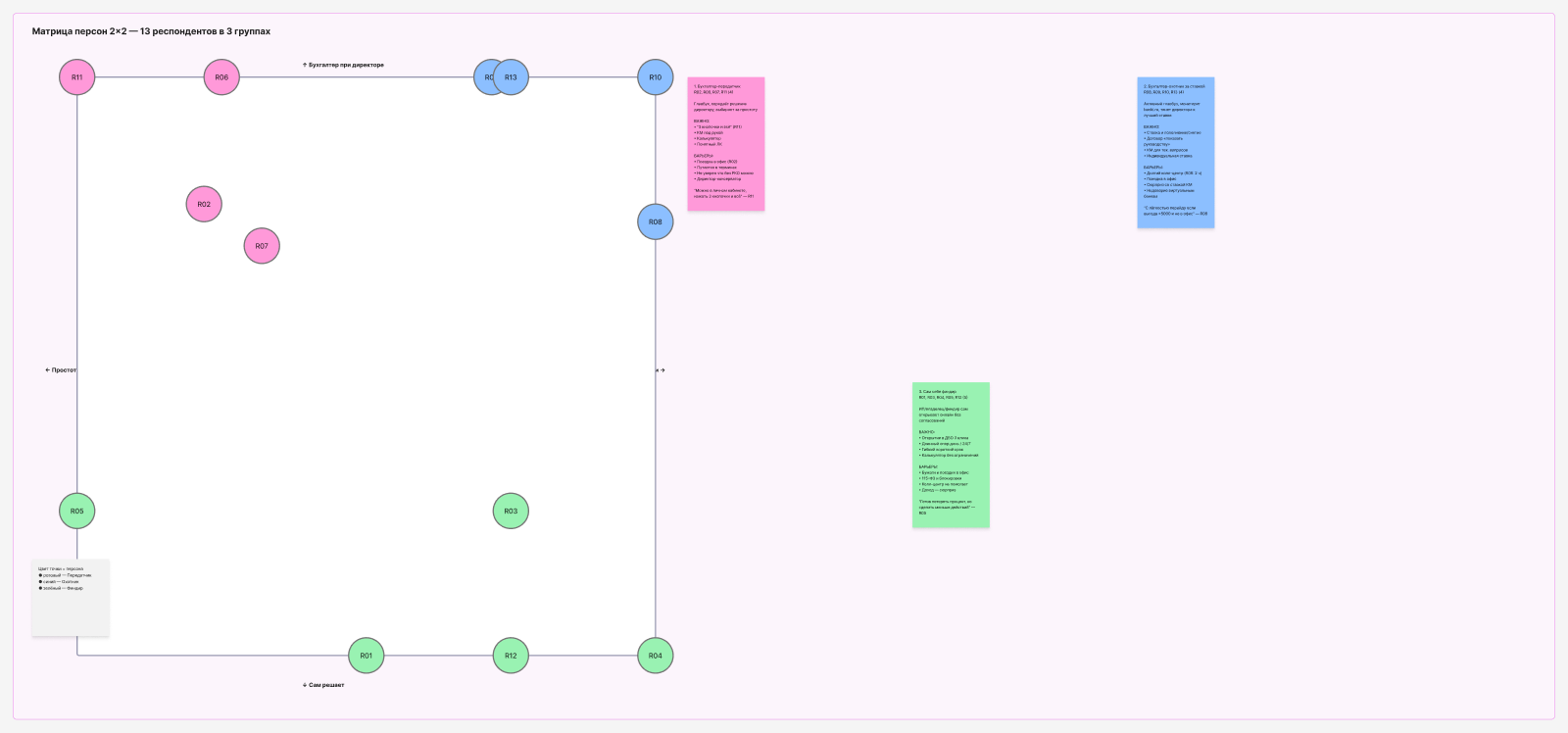
Agent version — different axes, complementary qualities
User Story Map — correct, but thin. I added a skill that expands stories into more concrete steps and re-ran it.
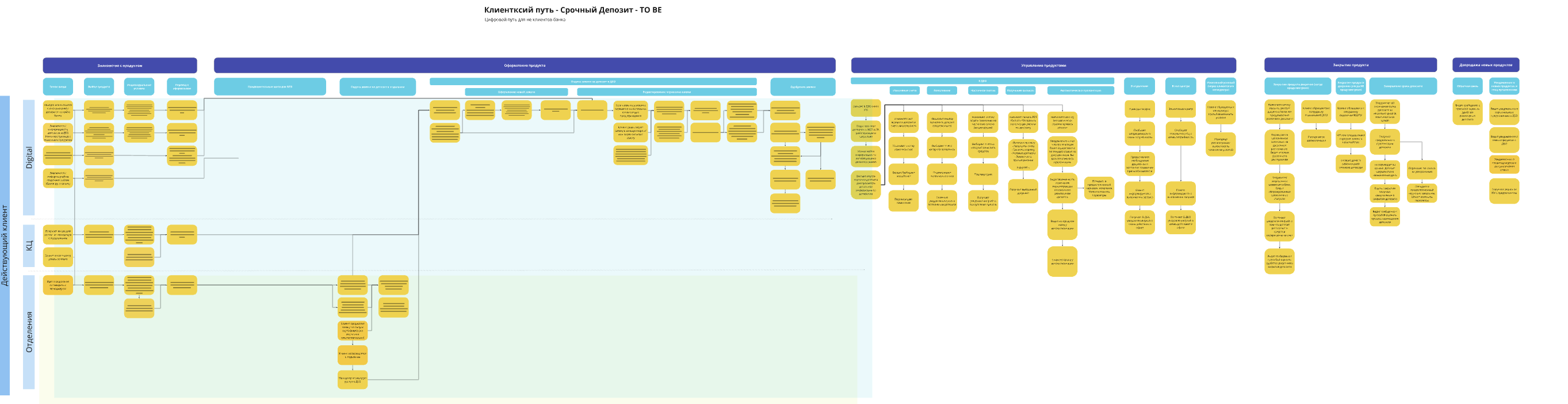
USM we built with the team and architects

Agent version after I added the expansion skill
Bottom line
- 3 hours — building the agents and skills
- 1 hour — testing and iteration
- Output — comparable to what the team did in 4 months
Caveat
In a real project the timeline is different: you need to sync with the team, feed the agent context carefully, and tune the skills to the product. Even so — the order of compression matches what I described in todayApproach on the VTB case: not "instead of the team," but "3 weeks instead of 4 months."